













幾十年來,計算機CPU芯片一直按照摩爾定律飛速發(fā)展,每隔十八個月,單位芯片面積上的晶體管數(shù)量就增加一倍,性能提高一倍。由于物理極限的限制,單純依靠制造工藝的提升已經(jīng)無法滿足計算需求,X86傳統(tǒng)計算平臺陷入了技術(shù)發(fā)展的瓶頸。內(nèi)存延時長、頻率低導(dǎo)致緩存面積越來越大,邏輯控制越來越復(fù)雜。緩存消耗了70%以上的芯片面積,同時也消耗了70%以上的電能,真正有效的運算部件面積比重很小。芯片上的晶體管密度越來越大,使得單位面積上功耗持續(xù)增加,散熱問題日益嚴重。
由于CPU的性能提升并不是無止境的,這也就催生出計算技術(shù)向多樣化發(fā)展,而不僅僅依賴于傳統(tǒng)的計算平臺。當計算技術(shù)進一步細化,GPU作為一種獨立的計算單元,以其優(yōu)異的運算性能脫穎而出,為計算技術(shù)的革新帶來了一種新的思路。
GPU計算是指利用圖形卡來進行一般意義上的計算,而不是傳統(tǒng)意義上的圖形繪制。時至今日,GPU已發(fā)展成為一種高度并行化、多線程、多核的處理器,具有杰出的計算功率和極高的存儲器帶寬,如圖所示。
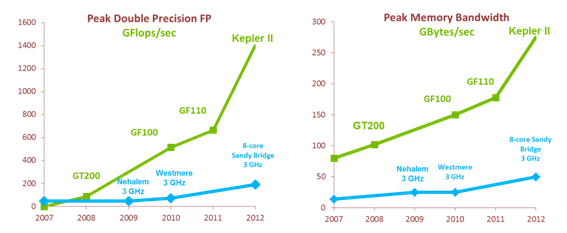
圖:CPU和GPU的每秒浮點運算次數(shù)和存儲器帶寬
這種新技術(shù)并非突破了馮?諾依曼,而是參考CPU中傳統(tǒng)的ALU單元,將眾多的ACL單元集成到一顆芯片內(nèi)部,形成ALU運算單元陣列,簡化邏輯控制結(jié)構(gòu),從而滿足計算密集型程序的運行,成為一個獨立的計算加速單元。
CPU和GPU之間浮點功能之所以存在這樣的差異,原因就在于GPU專為計算密集型、高度并行化的計算而設(shè)計,上圖顯示的正是這種情況,因而,GPU的設(shè)計能使更多晶體管用于數(shù)據(jù)處理,而非數(shù)據(jù)緩存和流控制,如圖所示。
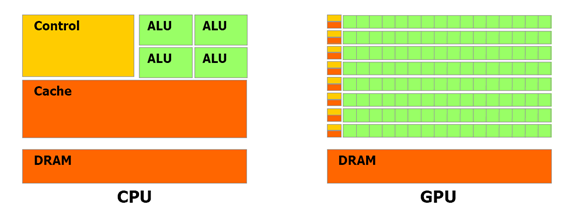
圖:GPU中的更多晶體管用于數(shù)據(jù)處理
GPU計算得到了業(yè)界的廣泛支持,NVIDIA、AMD、INTEL等都對芯片市場的微妙變化和GPU計算的技術(shù)發(fā)展前景都極為關(guān)注,并展開了激烈的技術(shù)競賽。
作為異構(gòu)計算領(lǐng)域堅定的支持者和踐行者,曙光公司從國內(nèi)第一套異構(gòu)集群開始到HC2000異構(gòu)計算方案的推出,一直在積極推進國內(nèi)HPC領(lǐng)域的異構(gòu)計算加速技術(shù)。
GPU計算方案配置選擇,主要考慮以下因素:
1. 計算比例,通常應(yīng)用程序的執(zhí)行需要GPU與CPU協(xié)同完成,可根據(jù)GPU計算部分所占比重,配置節(jié)點GPU卡密度;
2. 計算規(guī)模,根據(jù)不同應(yīng)用數(shù)據(jù)規(guī)模及計算類型,可以選擇單機單GPU卡、單機多GPU卡和GPU集群應(yīng)用模式;
3. 數(shù)據(jù)通信,在GPU集群模式下,可根據(jù)應(yīng)用程序?qū)和ㄐ艓捈把舆t的需求,選擇高速Infiniband網(wǎng)絡(luò)或萬兆網(wǎng)絡(luò);
4. 存儲系統(tǒng):單節(jié)點應(yīng)用模式下一般數(shù)據(jù)量比較小,對存儲系統(tǒng)性能要求不高,一般采用本地存儲;集群環(huán)境下,應(yīng)用數(shù)據(jù)量比較大,一般配置大容量、統(tǒng)一、高速的并行文件系統(tǒng),另外對一些特殊應(yīng)用,如石油、天然氣應(yīng)用,可以在每個GPU計算節(jié)點內(nèi)部配置SSD硬盤,作為分級存儲使用,加速節(jié)點內(nèi)部數(shù)據(jù)交換;
5. 管理調(diào)度,合理選擇GPU集群的作業(yè)調(diào)度和監(jiān)控系統(tǒng),可以提升集群的使用效率,降低維護成本。
版權(quán)所有:杭州天迪工控技術(shù)股份有限公司 地址:杭州市拱墅區(qū)科技工業(yè)園區(qū)康樂路11號A3棟
浙公網(wǎng)安備 33010602004930 浙ICP備11043394號


